Fit an STM topic model to a document collection
The topicsplorrr() package currently supports analyses of structural topic models created with the the versatile stm package (Roberts et al. 2014). stm builds on the tradition of popular topic modeling approaches like Latent Dirichlet Allocation (Blei, Ng, and Jordan 2003), but allows to incorporate other document metadata into the topic model (Roberts, Stewart, and Tingley 2019).
In order to explore an stm topic model with the help of the topicsplorrr() package a topic model needs to be fit and information on topic-document likelihoods and word-topic likelihoods needs to be extracted. The code below prepares a document collection, fits an stm topic model to this.
Consult the respective package documentation for more information on the terms_dfm() and stm::stm() methods. For later analyses it is also assumed that the original document data contains a date for each document.
library(topicsplorrr)
library(stm)
library(dplyr)
library(lubridate)
# a dataframe with documents
# use quanteda's inaugural presidential speeches as sampel data
sample_docs <- quanteda::convert(quanteda::data_corpus_inaugural,
to = "data.frame") %>%
mutate(Year = lubridate::as_date(paste(Year, "-01-20", sep = "")))
# a document feature matrix
sample_dfm <- terms_dfm(textData = sample_docs,
textColumn = "text", documentIdColumn = "doc_id",
removeStopwords = TRUE, removeNumbers = TRUE,
wordStemming = FALSE)
# fitting an STM topic model
sample_topics <- stm::stm(sample_dfm, K = 25)Topic likelihoods and labels
The stm() package provides several functions to explore the topic model. The plot function provides an overview of the topic model with expected topic proportions for the whole document collection and with the five most probable words for each topic.
plot(sample_topics, type = "summary", n = 5)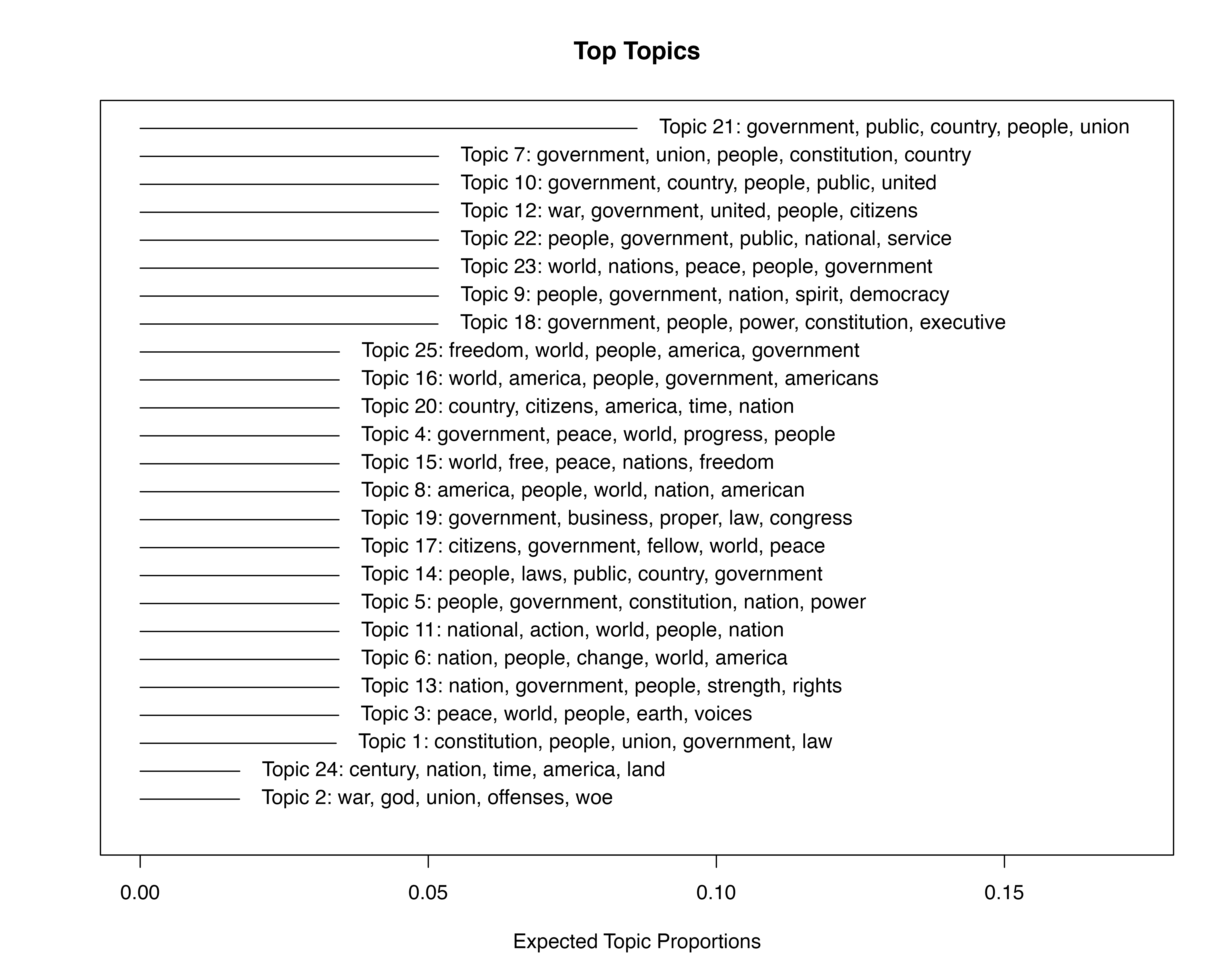
The topicsplorrr package provides some convenience methods to extract the same information for customized analyses and visualizations. With the help of the topics_by_doc_date function the topic likelihoods (or “shares”) for each document can be obtained. Below an example for the document set used so far.
topic_doc_shares <- topics_by_doc_date(sample_topics,
termsDfm = sample_dfm,
textData = sample_docs,
documentIdColumn = "doc_id",
dateColumn = "Year")Resulting in a dataframe with the following variables:
dplyr::glimpse(topic_doc_shares)
#> Rows: 1,450
#> Columns: 4
#> $ document <chr> "1789-Washington", "1789-Washington", "1789-Washington", "178…
#> $ occur <date> 1789-01-20, 1789-01-20, 1789-01-20, 1789-01-20, 1789-01-20, …
#> $ topic_id <chr> "13", "20", "7", "23", "19", "8", "22", "14", "15", "2", "3",…
#> $ gamma <dbl> 1.380049e-04, 5.758646e-05, 2.164318e-04, 5.813047e-05, 5.981…Useful topic labels can be generated with the help of most likely words associated with a topic. The following method is a simple wrapper around methods in the stm() package. As a default it returns the seven terms that are both most frequent and exclusive for a topic identified by ID.
topic_labels <- topics_terms_map(sample_topics)This information can be combined to create alternative visualizations, for example an interactive DT::datatable.
topic_means <- topics_summary(topic_doc_shares, topic_labels)
topic_means <- topics_summary(topic_doc_shares, topic_labels)
DT::datatable(topic_means,
options = list(pageLength = 10,
columnDefs = list(list(className = 'dt-left',
targets = "_all"))),
rownames = FALSE,
colnames = c("Topic ID", "Most representative words", "Mean topic probability")) %>%
DT::formatRound(3, digits = 4) %>%
DT::formatStyle(columns = c(1, 2, 3), fontSize = '90%') %>%
DT::formatStyle(columns = c(1, 3), 'text-align' = 'right') %>%
#DT::formatStyle(columns = c(1), width = '10%') %>%
#DT::formatStyle(columns = c(2), width = '60%') %>%
DT::formatStyle(3,
background = DT::styleColorBar(range(topic_means$mean_gamma), '#1964A6'),
backgroundSize = '100% 88%',
backgroundRepeat = 'no-repeat',
backgroundPosition = 'center')Temporal topic trends
One of the main objectives of topicsplorrr is to analyze temporal trends of topic models. The topics_by_doc_date() function extracts the topic likelihoods for each document-topic combination and merges this with the original document information, specifically the document identifiers and document publication date.
topic_doc_shares <- topics_by_doc_date(sample_topics,
termsDfm = sample_dfm,
textData = sample_docs,
documentIdColumn = "doc_id",
dateColumn = "Year")These can be used for custom analysis or a direct visualization of topical trends combining topics_terms_map() and plot_topic_frequencies().
# create a topic label set
topic_labels <- topicsplorrr::topics_terms_map(sample_topics, labelType = "prob")
# plot frequencies for all topics
topic_doc_shares %>%
plot_topic_frequencies(topN = 16, nCols = 4, selectTopicsBy = "most_frequent",
timeBinUnit = "year", topicLabels = topic_labels,
verboseLabels = FALSE)References
Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. “Latent dirichlet allocation.” The Journal of Machine Learning Research 3 (March): 993–1022. http://dl.acm.org/citation.cfm?id=944919.944937.
Roberts, Margaret E., Brandon M. Stewart, Dustin Tingley, Christopher Lucas, Jetson Leder-Luis, Shana Kushner Gadarian, Bethany Albertson, and David G. Rand. 2014. “Structural Topic Models for Open-Ended Survey Responses.” American Journal of Political Science 58 (4): 1064–82. https://doi.org/10.1111/ajps.12103.
Roberts, Margaret, Brandon Stewart, and Dustin Tingley. 2019. “Stm: An R Package for Structural Topic Models.” Journal of Statistical Software, Articles 91 (2): 1–40. https://doi.org/10.18637/jss.v091.i02.